Top 7 Lessons About Deepseek To Learn Before You Hit 30
페이지 정보

본문
DeepSeek (深度求索), founded in 2023, is a Chinese company devoted to creating AGI a actuality. Apple really closed up yesterday, as a result of DeepSeek is good news for the corporate - it’s proof that the "Apple Intelligence" guess, that we are able to run good enough native AI models on our telephones might truly work sooner or later. This means companies like Google, OpenAI, and Anthropic won’t be in a position to maintain a monopoly on entry to fast, low-cost, good high quality reasoning. Another set of winners are the large consumer tech corporations. We're additionally exploring the dynamic redundancy strategy for decoding. "Relative to Western markets, the fee to create high-high quality data is lower in China and there's a larger talent pool with college skills in math, programming, or engineering fields," says Si Chen, a vice president at the Australian AI firm Appen and a former head of technique at both Amazon Web Services China and the Chinese tech giant Tencent. In essence, reasonably than counting on the same foundational information (ie "the web") used by OpenAI, DeepSeek used ChatGPT's distillation of the identical to provide its enter. All in all, DeepSeek-R1 is both a revolutionary model within the sense that it is a new and apparently very effective method to coaching LLMs, and it's also a strict competitor to OpenAI, with a radically different approach for delievering LLMs (far more "open").
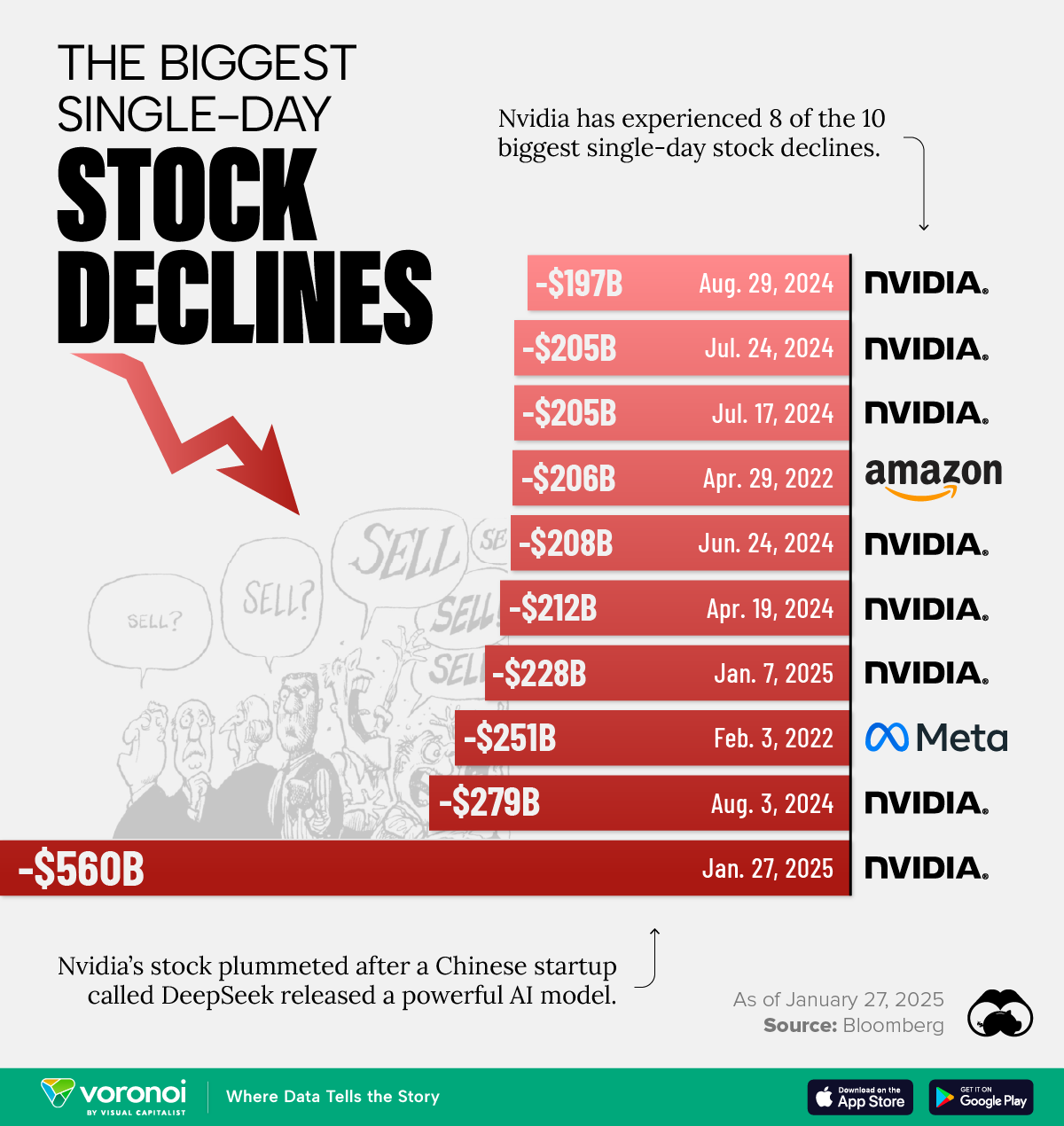 The important thing takeaway is that (1) it's on par with OpenAI-o1 on many duties and benchmarks, (2) it's absolutely open-weightsource with MIT licensed, and (3) the technical report is available, and paperwork a novel end-to-finish reinforcement studying strategy to training giant language mannequin (LLM). I confirm that it is on par with OpenAI-o1 on these duties, although I find o1 to be slightly better. DeepSeek is a powerful AI device designed to assist with varied duties, from programming help to data analysis. One plausible purpose (from the Reddit post) is technical scaling limits, like passing information between GPUs, or dealing with the amount of hardware faults that you’d get in a training run that size. HBM, and the fast data access it allows, has been an integral a part of the AI story nearly since the HBM's commercial introduction in 2015. More not too long ago, HBM has been built-in straight into GPUs for AI purposes by benefiting from superior packaging applied sciences akin to Chip on Wafer on Substrate (CoWoS), that further optimize connectivity between AI processors and HBM. And then there have been the commentators who are actually price taking severely, as a result of they don’t sound as deranged as Gebru. I’m positive AI people will find this offensively over-simplified however I’m attempting to maintain this comprehensible to my brain, let alone any readers who do not have stupid jobs the place they'll justify reading blogposts about AI all day.
The important thing takeaway is that (1) it's on par with OpenAI-o1 on many duties and benchmarks, (2) it's absolutely open-weightsource with MIT licensed, and (3) the technical report is available, and paperwork a novel end-to-finish reinforcement studying strategy to training giant language mannequin (LLM). I confirm that it is on par with OpenAI-o1 on these duties, although I find o1 to be slightly better. DeepSeek is a powerful AI device designed to assist with varied duties, from programming help to data analysis. One plausible purpose (from the Reddit post) is technical scaling limits, like passing information between GPUs, or dealing with the amount of hardware faults that you’d get in a training run that size. HBM, and the fast data access it allows, has been an integral a part of the AI story nearly since the HBM's commercial introduction in 2015. More not too long ago, HBM has been built-in straight into GPUs for AI purposes by benefiting from superior packaging applied sciences akin to Chip on Wafer on Substrate (CoWoS), that further optimize connectivity between AI processors and HBM. And then there have been the commentators who are actually price taking severely, as a result of they don’t sound as deranged as Gebru. I’m positive AI people will find this offensively over-simplified however I’m attempting to maintain this comprehensible to my brain, let alone any readers who do not have stupid jobs the place they'll justify reading blogposts about AI all day.
For instance, here’s Ed Zitron, a PR guy who has earned a repute as an AI sceptic. Jeffrey Emanuel, the guy I quote above, actually makes a really persuasive bear case for Nvidia at the above link. His language is a bit technical, and there isn’t a great shorter quote to take from that paragraph, so it might be simpler simply to assume that he agrees with me. The very current, state-of-art, open-weights model DeepSeek R1 is breaking the 2025 news, glorious in lots of benchmarks, with a new integrated, end-to-end, reinforcement studying strategy to giant language mannequin (LLM) coaching. And this isn't even mentioning the work within Deepmind of making the Alpha mannequin series and making an attempt to incorporate those into the large Language world. 2025 might be nice, so perhaps there will probably be much more radical adjustments within the AI/science/software program engineering landscape. For certain, it will radically change the panorama of LLMs. So positive, if DeepSeek heralds a new period of a lot leaner LLMs, it’s not great news within the short time period if you’re a shareholder in Nvidia, Microsoft, Meta or Google.6 But if DeepSeek is the enormous breakthrough it appears, it simply became even cheaper to practice and use the most subtle fashions people have thus far built, by one or more orders of magnitude.
While tech analysts broadly agree that DeepSeek-R1 performs at the same degree to ChatGPT - or even higher for sure duties - the sector is shifting quick. Discover the important thing variations between ChatGPT and Free DeepSeek v3. Like all different Chinese AI models, DeepSeek self-censors on matters deemed sensitive in China. The subsequent iteration of OpenAI’s reasoning fashions, o3, seems way more powerful than o1 and can quickly be available to the general public. Introducing DeepSeek, OpenAI’s New Competitor: A Full Breakdown of Its Features, Power, and… From now on, we're also exhibiting v0's full output in each response. To know what’s so spectacular about DeepSeek, one has to look back to final month, when OpenAI launched its personal technical breakthrough: the full release of o1, a new sort of AI mannequin that, in contrast to all the "GPT"-style applications before it, seems capable of "reason" by difficult problems. Also, with any lengthy tail search being catered to with more than 98% accuracy, you too can cater to any deep Seo for any type of keywords. But if o1 is more expensive than R1, being able to usefully spend extra tokens in thought might be one reason why.
- 이전글دبلوم إعداد مدرب اللياقة البدنية المعتمد 25.03.01
- 다음글방앗간 우회주소エ 연결 (DVD_16k)방앗간 우회주소エ #2c 방앗간 우회주소エ 무료 25.03.01
댓글목록
등록된 댓글이 없습니다.