Methods to Lose Cash With Deepseek
페이지 정보

본문
DeepSeek exhibits that quite a lot of the trendy AI pipeline will not be magic - it’s consistent beneficial properties accumulated on cautious engineering and choice making. For finest performance, a modern multi-core CPU is advisable. The key is to have a moderately fashionable consumer-level CPU with decent core rely and clocks, together with baseline vector processing (required for CPU inference with llama.cpp) by means of AVX2. If your system does not have quite enough RAM to totally load the model at startup, you may create a swap file to help with the loading. The DDR5-6400 RAM can provide up to 100 GB/s. I've had lots of people ask if they will contribute. Here is how one can create embedding of documents. 64k extrapolation not reliable here. Documentation on installing and utilizing vLLM might be found right here. On this weblog, I'll guide you thru establishing DeepSeek-R1 on your machine using Ollama. Because of the performance of each the big 70B Llama 3 model as properly as the smaller and self-host-in a position 8B Llama 3, I’ve really cancelled my ChatGPT subscription in favor of Open WebUI, a self-hostable ChatGPT-like UI that permits you to use Ollama and other AI suppliers while retaining your chat historical past, prompts, and different information locally on any laptop you control.
 DeepSeek Coder V2 is being offered underneath a MIT license, which allows for each research and unrestricted business use. However, there are a number of potential limitations and areas for additional analysis that may very well be thought-about. I will consider adding 32g as properly if there may be interest, and once I have done perplexity and evaluation comparisons, but right now 32g models are nonetheless not fully examined with AutoAWQ and vLLM. Like other AI startups, including Anthropic and Perplexity, DeepSeek released various competitive AI models over the previous year that have captured some industry attention. For example, RL on reasoning could improve over more training steps. I believe that is such a departure from what is thought working it may not make sense to discover it (coaching stability could also be really laborious). If the 7B model is what you're after, you gotta assume about hardware in two ways. When operating deepseek ai china AI fashions, you gotta listen to how RAM bandwidth and mdodel size affect inference velocity. Suppose your have Ryzen 5 5600X processor and DDR4-3200 RAM with theoretical max bandwidth of fifty GBps. But I might say each of them have their very own claim as to open-source fashions that have stood the test of time, a minimum of on this very brief AI cycle that everybody else exterior of China continues to be using.
DeepSeek Coder V2 is being offered underneath a MIT license, which allows for each research and unrestricted business use. However, there are a number of potential limitations and areas for additional analysis that may very well be thought-about. I will consider adding 32g as properly if there may be interest, and once I have done perplexity and evaluation comparisons, but right now 32g models are nonetheless not fully examined with AutoAWQ and vLLM. Like other AI startups, including Anthropic and Perplexity, DeepSeek released various competitive AI models over the previous year that have captured some industry attention. For example, RL on reasoning could improve over more training steps. I believe that is such a departure from what is thought working it may not make sense to discover it (coaching stability could also be really laborious). If the 7B model is what you're after, you gotta assume about hardware in two ways. When operating deepseek ai china AI fashions, you gotta listen to how RAM bandwidth and mdodel size affect inference velocity. Suppose your have Ryzen 5 5600X processor and DDR4-3200 RAM with theoretical max bandwidth of fifty GBps. But I might say each of them have their very own claim as to open-source fashions that have stood the test of time, a minimum of on this very brief AI cycle that everybody else exterior of China continues to be using.
The publisher of these journals was a type of unusual enterprise entities where the entire AI revolution seemed to have been passing them by. It was also just a little bit emotional to be in the identical type of ‘hospital’ because the one which gave delivery to Leta AI and GPT-three (V100s), ChatGPT, GPT-4, DALL-E, and far more. Note that the GPTQ calibration dataset will not be the identical as the dataset used to practice the model - please seek advice from the original mannequin repo for particulars of the training dataset(s). Other songs hint at more serious themes (""Silence in China/Silence in America/Silence in the very best"), however are musically the contents of the same gumball machine: crisp and measured instrumentation, with just the correct quantity of noise, scrumptious guitar hooks, and synth twists, every with a distinctive coloration. It’s a part of an necessary movement, after years of scaling models by elevating parameter counts and amassing larger datasets, towards reaching high performance by spending extra power on generating output. Remember, these are recommendations, and the actual performance will rely on several components, including the precise task, mannequin implementation, and different system processes. Conversely, GGML formatted fashions will require a big chunk of your system's RAM, nearing 20 GB.
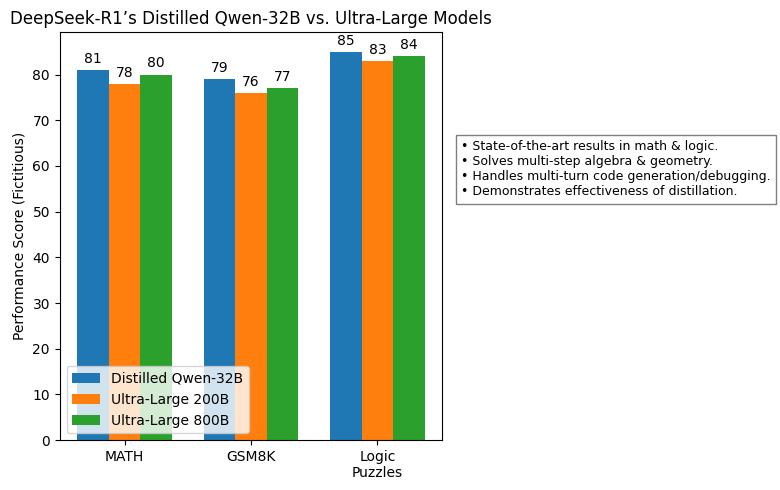 Remember, whereas you can offload some weights to the system RAM, it's going to come at a performance cost. Having CPU instruction sets like AVX, AVX2, AVX-512 can further improve efficiency if out there. Explore all versions of the mannequin, their file codecs like GGML, GPTQ, and HF, and understand the hardware necessities for native inference. Not required for inference. In comparison with GPTQ, it gives faster Transformers-primarily based inference with equivalent or better high quality compared to the mostly used GPTQ settings. To attain a better inference velocity, say 16 tokens per second, you would wish more bandwidth. On this situation, you'll be able to expect to generate roughly 9 tokens per second. The educational charge begins with 2000 warmup steps, and then it's stepped to 31.6% of the maximum at 1.6 trillion tokens and 10% of the maximum at 1.Eight trillion tokens. The important thing contributions of the paper include a novel approach to leveraging proof assistant suggestions and developments in reinforcement studying and search algorithms for theorem proving. This feature broadens its functions across fields corresponding to real-time weather reporting, translation providers, and computational duties like writing algorithms or code snippets. It is licensed under the MIT License for the code repository, with the utilization of fashions being topic to the Model License.
Remember, whereas you can offload some weights to the system RAM, it's going to come at a performance cost. Having CPU instruction sets like AVX, AVX2, AVX-512 can further improve efficiency if out there. Explore all versions of the mannequin, their file codecs like GGML, GPTQ, and HF, and understand the hardware necessities for native inference. Not required for inference. In comparison with GPTQ, it gives faster Transformers-primarily based inference with equivalent or better high quality compared to the mostly used GPTQ settings. To attain a better inference velocity, say 16 tokens per second, you would wish more bandwidth. On this situation, you'll be able to expect to generate roughly 9 tokens per second. The educational charge begins with 2000 warmup steps, and then it's stepped to 31.6% of the maximum at 1.6 trillion tokens and 10% of the maximum at 1.Eight trillion tokens. The important thing contributions of the paper include a novel approach to leveraging proof assistant suggestions and developments in reinforcement studying and search algorithms for theorem proving. This feature broadens its functions across fields corresponding to real-time weather reporting, translation providers, and computational duties like writing algorithms or code snippets. It is licensed under the MIT License for the code repository, with the utilization of fashions being topic to the Model License.
If you beloved this article therefore you would like to receive more info about ديب سيك please visit our web-page.
- 이전글59% Of The Market Is Fascinated with Deepseek 25.02.01
- 다음글【mt1414.shop】안전한 시알리스 구매방법 25.02.01
댓글목록
등록된 댓글이 없습니다.